Lab lock
- 10 mins1 Memory allocator (moderate)
修改kalloc机制,使得每个CPU拥有自己的内存空闲列表,而不是共用一个空闲列表而降低效率
1.1 机制设计
- 初始化:将整个物理的空闲页面全部分配给CPU0。
- 分配:查询当前CPU的空闲列表。如果列表不为空,则我们拿出一个空闲页面。如果列表为空,我们查询其他CPU的空闲列表,直到查遍所有CPU的列表。如果所以CPU列表为空,则分配失败。
- 释放:将要释放的页面插入到当前CPU的空闲列表中。
关键部分是如何(抢劫)其他CPU的空间
1.2 初始化
初始化所有CPU空闲链表的锁。并将所有空闲页面分配给CPU0,(最初只有CPU0在运行,所以kalloc时的cpuid一定是0,所以不用在意freerange),只用修改kinit函数。
代码如下:
void
kinit()
{
for (int i = 0; i < NCPU; ++i) {
initlock(&kmem[i].lock, "kmem");
}
freerange(end, (void *)PHYSTOP);
}
1.3 分配
从当前进程所在的CPU开始,查询所有的CPU的空闲列表,如果存在空闲页面,则分配成功,结束循环。因为存在竞争问题,所以查询空闲列表的时候需要相应CPU列表的锁。
代码:
void *
kalloc(void)
{
struct run *r;
push_off();
int cpuindex = cpuid();
int index = cpuindex;
pop_off();
for (int i = 0; i < NCPU; ++i) {
acquire(&kmem[index].lock);
r = kmem[index].freelist;
if(r)
kmem[index].freelist = r->next;
release(&kmem[index].lock);
if (r) {
break;
}
index = (index + 1) % NCPU;
}
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
1.4 释放
将要释放的页面插入到当前进程所在的CPU空闲链表中即可。
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
push_off();
int cpuindex = cpuid();
pop_off();
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem[cpuindex].lock);
r->next = kmem[cpuindex].freelist;
kmem[cpuindex].freelist = r;
release(&kmem[cpuindex].lock);
}
2 buffer cache (hard)
在xv6的文件系统实现中,将文件系统分成了7层。
而作为第二层的
buffer cache层,需要完成以下两个工作:
- 确保每时每刻每个磁盘块只有一个缓存在缓存层,而且只能有一个内核线程在使用这个缓存块。
- 缓存经常使用的块,这样这些块就不需要每次从磁盘读取。
本实验需要你优化现有的缓存层机制,减少锁竞争,优化查找速度。
现有的机制不足之处是,查找一个块是否缓存需要查遍整个缓存区,不仅查找效率低,而且占用锁的时间长,容易产生锁竞争。
本实验采用的优化方法是,使用哈希桶。每个块号对应一个哈希桶,直接在哈希桶里查找,不仅减小了搜索量,而且每次查找只需要这一个哈希桶的锁,大大降低了锁冲突的可能性。
由于本实验和上半个实验间隔有点,完成的断断续续,思路不够连续。
总体本实验代码经过了四个版本,重写了很多次,主要卡在了第三个版本,自己感觉很合理,但是没有遵循缓存层的第一要求。也通过这一个版本,大致明白了这个实验的hints是什么意思。

2.1 V1.0
2.1.1 思路
直接为每个桶建立链表,并没有维护删除失效的节点。
2.1.2 问题
可想而知,这个版本思维漏洞很多。所以我写完发现没有测试通过直接放弃了。
2.2 V2.0
2.2.1 思路
经过1.0之后,我觉得并没有必要维护一个buf链表呀,我可以以磁盘块号为第一关键字,设备号为第2关键字,维护一个磁盘块对应的buf下标就可以了。
2.2.2 问题
最大问题还是自己偷懒没有维护失效的信息。后来我也发现这是一个大问题,导致最后即使通过哈希表找到的对应buf的编号,这个buf也可能是失效的。
再次尝试了一下两个方向的修改:
- 即使在哈希表中找到对应的buf的下标,也要检查这个下标是不是有效的(通过检查buf的块号和设备号)
- 或许可以维护一个buf对应的桶标签,或许通过检查这个桶标签来判断是不是有效的
但是这个修改带来的问题很多,还是不能确定有效的确定这个buf是不是有效的(还是没有从链表中删除,可能该块被使用后又被另一个块使用后再被这个块使用,1-2-1),而且节点信息重复。总之,感觉问题蛮多。
2.3 V3.0
2.3.1 思路
这个思路更偷懒了,大致思路还是依照2.0版本的,想到每个桶中有重复的节点,而且感觉不好理解,不如每个桶不维护链表了,直接每个桶只能放一个元素,当有新元素要使用这个桶的时候,直接覆盖掉原来的信息即可。
2.3.2 问题
写了好多好多遍,感觉没有没有问题,如果在不在桶中意思是最近没有使用了呀,那么我直接遍历所有buf块,看看有没有没有没被使用,然后分配这个空闲块给他,然后更新哈希桶就行了呀。
但是得到的反馈是,操作系统能够正常的启动,但是,一做测试就得到bget的panic,没有可以使用的buf了,怎么回事呢。
后来想想,如果在桶中没有匹配到,那么我找到新的块之后,暴力驱逐桶中的块(这个块可能还在被使用),更新为新的块,那么当原来的块又要再次使用的时候,发现桶中没有了,以为不在缓存层中了,然后去找的新的块,重新从磁盘中获取这个块。此时,缓存层中就有两个相同的磁盘块,违背了缓存层的第一个工作要求,每个磁盘块只能有一个缓存在缓存层中。
这个思路宣告破产
2.3.3 总结
- 看来还是得像第一版一样维护一个buf链表。
- 必须存在删除失效块,并且重新分配这个失效块到链表中。
2.4 V4.0
放弃偷懒想法,回归版本一。
2.4.1 初始化表
初始化哈希表如下:
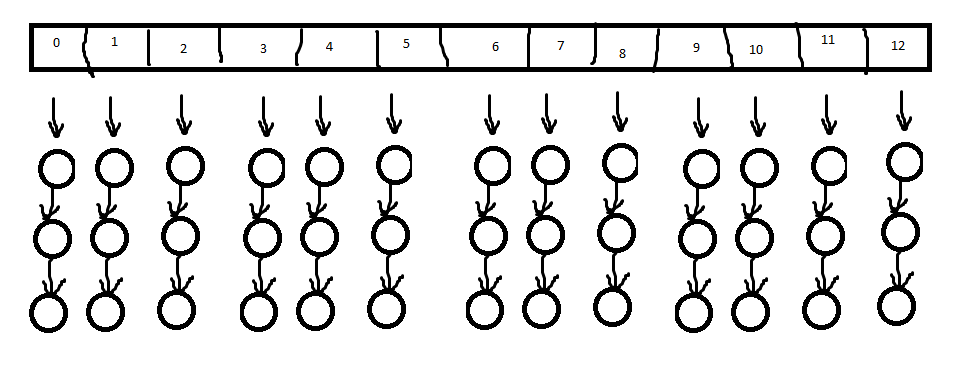
一般而言,哈希桶的个数为质数个,这里选用了hints中的个数13。
每个桶分配三个空闲节点,这些节点的依次对应buf数组的每个元素。这里需要39节点,而param.h中宏定义的30个不够,所以我们把他改成39。
2.4.2 查找缓存
找到块号对应的桶,获取桶锁,遍历整个桶,如果找到了对应的缓存,块的引用计数加一,释放桶锁,获取块锁,返回该块。
2.4.3 未命中
若没有查询到缓存,则查找该桶中有没有空闲的块,若有,修改该块的信息(块号,设备号,有效位),引用计数设置为1,释放桶锁,获取块锁,返回该块。
如果该桶中没有空闲块,那只能从其他桶中释放空闲块了。
此时我们要释放该桶的锁,因为后面同时需要两个锁,我们先释放这个锁,一遍其他内核线程可以使用这个桶。还有一个原因是,后面我们查找其他桶的空闲块的时候,也不需要一直拿到这个锁,直到查找到一个空闲块后,我们才需要这个锁,将这个空闲块,插入到这个桶的链表中。
2.4.4 跨桶查找并驱逐
!important考虑这样一种死锁情况:当桶1在桶2中查找空闲块的时候需要桶2的锁,而这个时候桶2要查找桶1中的空闲块的时候,需要桶1的锁,这个时候,两个线程互相等待,导致死锁。所以我门需要一个锁,保证一个时刻,只有一个内核线程在跨桶查找。
或许这个就是hints里的bcache lock的用处吧,我到这一步才理解这个意思。(之前想不懂有bucket锁后我还需要bcache锁干什么呢)
当之前的步骤没有查找到空闲块的时候,我们就需要跨桶查找,此时我们要先获得一个跨桶查找锁。不如就使用bcache锁。
查找每一个桶:获取当前桶的桶锁,查询有无空闲块。若有,我们从桶中删除这个块,释放桶锁。获取原来的桶锁,将该块插入到链表中,修改该块的信息,引用计数设置为1,释放桶锁,释放跨桶查找锁,获得块锁,返回该块。若在该桶中没有查询到空闲块,则释放该桶锁,继续下一个桶。
若所有的桶均没有空闲块,则真就没有空闲块了,就简单的panic吧。
2.4.5 修改其他函数
按照hints的说法,删去所有的LRU算法相关的代码。
了解每个锁保护的对象
- 对于跨桶查找锁:保证了每个时刻只能有一个内核线程进行跨桶查找。
- 对于桶锁:保护整个桶的链表,而且保证每个buf只能有一个内核线程进行读或写。
所以,修改其他函数,当他们要修改buf相关信息时,或得对应的桶锁。
2.5 代码
bio.c
// Buffer cache.
//
// The buffer cache is a linked list of buf structures holding
// cached copies of disk block contents. Caching disk blocks
// in memory reduces the number of disk reads and also provides
// a synchronization point for disk blocks used by multiple processes.
//
// Interface:
// * To get a buffer for a particular disk block, call bread.
// * After changing buffer data, call bwrite to write it to disk.
// * When done with the buffer, call brelse.
// * Do not use the buffer after calling brelse.
// * Only one process at a time can use a buffer,
// so do not keep them longer than necessary.
#include "types.h"
#include "param.h"
#include "spinlock.h"
#include "sleeplock.h"
#include "riscv.h"
#include "defs.h"
#include "fs.h"
#include "buf.h"
#define HASHMAP(number) (number % NBUCKET)
struct {
struct spinlock lock;
struct buf buf[NBUF];
struct {
struct spinlock lock;
struct buf head;
} bucket[NBUCKET];
} bcache;
void
binit(void)
{
struct buf *b;
initlock(&bcache.lock, "bcache.eviction");
for (int i = 0; i < NBUCKET; ++i) {
initlock(&bcache.bucket[i].lock, "bcache.bucket");
bcache.bucket[i].head.next = 0;
b = &bcache.bucket[i].head;
for (int j = i * 3; j < i * 3 + 3; j++) {
initsleeplock(&bcache.buf[j].lock, "buffer");
bcache.buf[j].next = b->next;
b->next = &bcache.buf[j];
b = b->next;
}
}
}
// Look through buffer cache for block on device dev.
// If not found, allocate a buffer.
// In either case, return locked buffer.
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
int index = HASHMAP(blockno);
acquire(&bcache.bucket[index].lock);
for (b = bcache.bucket[index].head.next; b; b = b->next) {
if (b->blockno == blockno && b->dev == dev) {
b->refcnt++;
release(&bcache.bucket[index].lock);
acquiresleep(&b->lock);
return b;
}
}
for (b = bcache.bucket[index].head.next; b; b = b->next) {
if (b->refcnt == 0) {
b->blockno = blockno;
b->dev = dev;
b->valid = 0;
b->refcnt = 1;
release(&bcache.bucket[index].lock);
acquiresleep(&b->lock);
return b;
}
}
release(&bcache.bucket[index].lock);
acquire(&bcache.lock);
for (int i = 0; i < NBUCKET; ++i) {
if (i != index) {
struct buf *pre;
acquire(&bcache.bucket[i].lock);
for (pre = &bcache.bucket[i].head, b = bcache.bucket[i].head.next; b; pre = b, b = b->next) {
if (b->refcnt == 0) {
pre->next = b->next;
release(&bcache.bucket[i].lock);
acquire(&bcache.bucket[index].lock);
b->next = bcache.bucket[index].head.next;
bcache.bucket[index].head.next = b;
b->blockno = blockno;
b->dev = dev;
b->valid = 0;
b->refcnt = 1;
release(&bcache.bucket[index].lock);
acquiresleep(&b->lock);
release(&bcache.lock);
return b;
}
}
release(&bcache.bucket[i].lock);
}
}
release(&bcache.lock);
panic("bget: no buffers");
}
// Return a locked buf with the contents of the indicated block.
struct buf*
bread(uint dev, uint blockno)
{
struct buf *b;
b = bget(dev, blockno);
if(!b->valid) {
virtio_disk_rw(b, 0);
b->valid = 1;
}
return b;
}
// Write b's contents to disk. Must be locked.
void
bwrite(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("bwrite");
virtio_disk_rw(b, 1);
}
// Release a locked buffer.
// Move to the head of the most-recently-used list.
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
int index = HASHMAP(b->blockno);
releasesleep(&b->lock);
acquire(&bcache.bucket[index].lock);
b->refcnt--;
release(&bcache.bucket[index].lock);
}
void
bpin(struct buf *b) {
int index = HASHMAP(b->blockno);
acquire(&bcache.bucket[index].lock);
b->refcnt++;
release(&bcache.bucket[index].lock);
}
void
bunpin(struct buf *b) {
int index = HASHMAP(b->blockno);
acquire(&bcache.bucket[index].lock);
b->refcnt--;
release(&bcache.bucket[index].lock);
}
buf.h
struct buf {
int valid; // has data been read from disk?
int disk; // does disk "own" buf?
uint dev;
uint blockno;
struct sleeplock lock;
uint refcnt;
struct buf *next;
uchar data[BSIZE];
};
param.h
#define NPROC 64 // maximum number of processes
#define NCPU 8 // maximum number of CPUs
#define NOFILE 16 // open files per process
#define NFILE 100 // open files per system
#define NINODE 50 // maximum number of active i-nodes
#define NDEV 10 // maximum major device number
#define ROOTDEV 1 // device number of file system root disk
#define MAXARG 32 // max exec arguments
#define MAXOPBLOCKS 10 // max # of blocks any FS op writes
#define LOGSIZE (MAXOPBLOCKS*3) // max data blocks in on-disk log
#define NBUF (MAXOPBLOCKS*3 + 9) // size of disk block cache
#define FSSIZE 2000 // size of file system in blocks
#define MAXPATH 128 // maximum file path name
#define NBUCKET 13
3 END
断断续续,长达一个信息才写完这个实验,测试结果如下。
== Test running kalloctest ==
$ make qemu-gdb
(116.6s)
== Test kalloctest: test1 ==
kalloctest: test1: OK
== Test kalloctest: test2 ==
kalloctest: test2: OK
== Test kalloctest: test3 ==
kalloctest: test3: OK
== Test kalloctest: sbrkmuch ==
$ make qemu-gdb
kalloctest: sbrkmuch: OK (14.0s)
== Test running bcachetest ==
$ make qemu-gdb
(22.4s)
== Test bcachetest: test0 ==
bcachetest: test0: OK
== Test bcachetest: test1 ==
bcachetest: test1: OK
== Test usertests ==
$ make qemu-gdb
usertests: OK (78.4s)
== Test time ==
time: OK
Score: 80/80

Pei Meng
Someone who interested in Computer Architecture.