分支预测
- 1 min对《超标量处理器设计》的第4章分支预测一些笔记整理。
思维导图:
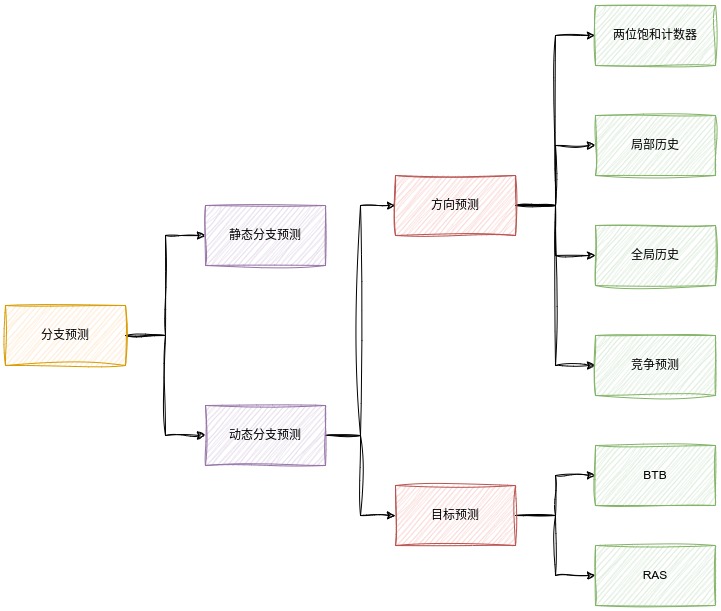
分支预测的类型
不用等到分支指令的结果真的被计算出来,而是提前就预测结果的过程就是分支预测。分支预测分为静态分支预测以及动态分支预测。
- 静态分支预测:认为分支预测一定发生跳转或者一定不发生跳转的预测是静态分支预测。
- 动态分支预测:并不会简单地预测分支指令一直发生跳转或者不跳转,而是会根据分支指令在过去的一段时间的执行情况来决定预测的结果。
要预测首先需要知道该指令是一条分支指令。获取到这个信息的方式是在取指的时候先进行预译码。
分支指令的方向预测
基于两位饱和计数器的分支预测
原型是基于一位计数器的分支预测,即上次怎么做我这次就怎么做。这种方式的问题在于,一但分支预测具有一定周期性规律,这种预测方式的准确率就很低。对其改进的方式就是,再添加一位,使用两位饱和计数器。
原理
此时,计数器就会出现以下四种情况:00,01,10,11,我们也对其定义为四种状态,强不跳转,弱不跳转,弱跳转,强跳转。当在其状态的时候,分别采用以下的预测策略:不跳转,不跳转,跳转,跳转。这四个状态之间的转换状态机图如下:

还有两种比较常用的状态机:
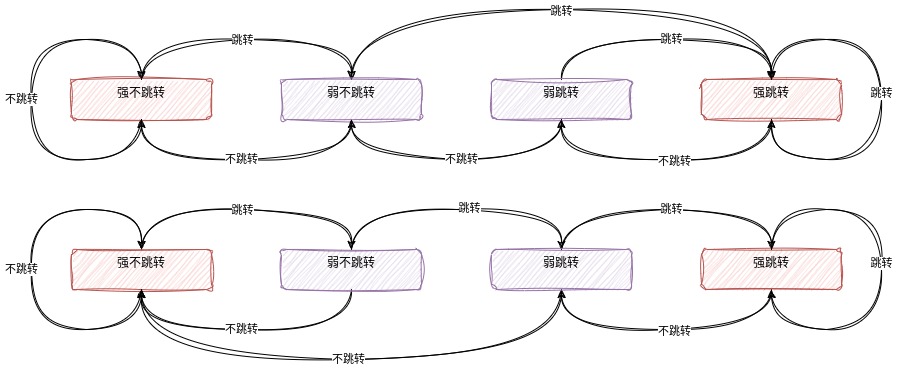
那么最初的时候应该使用什么状态呢?一般来说,会使用两个弱状态中的一种。
这种分支预测的好处:偶尔一次的分支方向变化不会影响分支预测,准确率很高。所以该方法也是现在主流的分支预测方法。
预测
有了原理,我们如何对一条分支指令进行方向预测呢?每一条指令都有一个PC值,我们可以以PC值为索引,建立一个数组,存放每个PC的两位饱和计数器。我们称这样一个数组为PHT(Pattern History Table)。
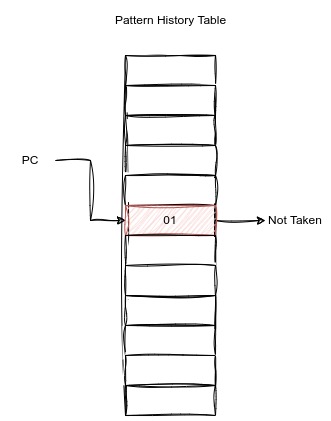
但是这样的做法有一个问题,PC的范围非常的大,不可能为全部的PC提供两位饱和计数器存储的位置,所以我们需要对PC值进行一些处理。一般会有以下几种处理方式:
- 切片:选取PC二进制中的k位,作为索引值。
- 哈希:使用hash算法,将PC转化为一个较小的值。
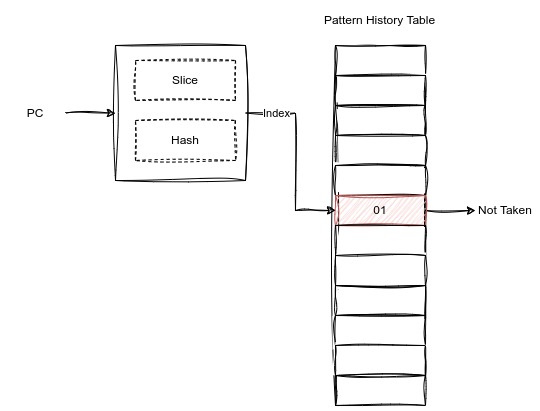
这样操作之后,难免会碰到这种情况:两个PC值对应的PHT的entry是一样的。这就是重名问题。如果重名对跳转的结果不产生影响,则该重名是一个中立的重名;如果该重名对跳转的结果造成了影响,则该重名是一个破坏性的重名。
总结
该方法实现简单,准确率高。但是准确率有极限值,不超过98%。
基于局部历史的分支预测
可以说,基于两位饱和计数器的分支预测器是该方法的一种特殊情况,即不考虑历史分支情况。现在我们要考虑一条指令历史的执行情况,就产生了基于局部历史的分支预测。
原理
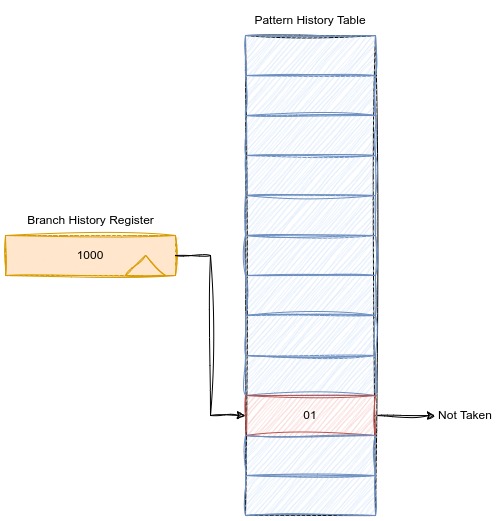
为每一条分支指令维护一个分支历史寄存器(Branch History Register),位宽为b位,表示历史b次执行情况。假设$b = 4$,寄存器的值为1000,表示执行情况为跳转,不跳转,不跳转,不跳转。
然后,为每一种历史4次执行情况维护一个2为饱和计数器,根据该计数器的值决定是否跳转。饱和计数器的个数为$2 ^ b$个。此时的原理和基于两位饱和计数器的分支预测原理一样了。
如果我们为每个PC都维护一个BHT,同时也维护一个PHT,则效果会如下:
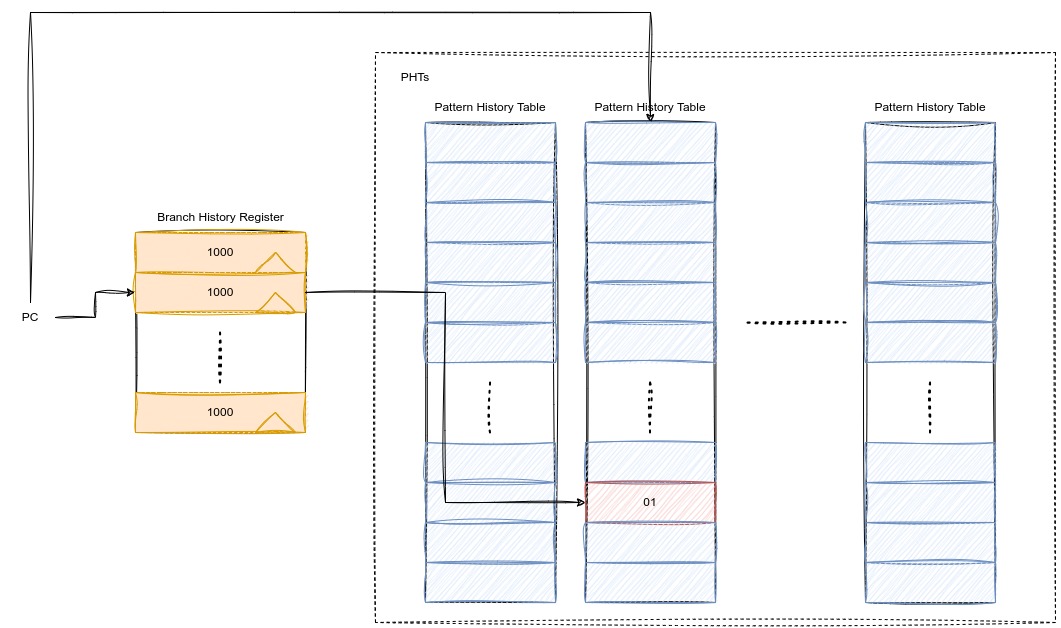
这样做法会导致硬件开销非常的大,我们可以进行一些改进。
改进
第一种方式,我们仍然维护多个PHT,但不再使用PC寻找BHR和PHT。仿照之前的做法,对PC进行切片,取其中的p位寻址BHR,其中的q位来寻址PHT。此时我们就只需要维护$2^q$个PHT。但是会引入重名问题。
第二种方式,我们只用维护一个PHT,但是会增加PHT的entry的个数。此时的问题是,我们如何根据PC获取一个entry的索引值。有一下几种方式:
- PC的哈希值拼接BHR值。$index = cat(hash(PC), BHR(hash(PC)))$
- PC的部分值拼接BHR部分值。$index = cat(PC[k, 0], BHR(hash(PC))[k, 0])$
- PC的部分值拼接BHR部分值。$index = PC[k, 0] \bigotimes BHR(hash(PC))[k, 0]$
通常来讲,第三种方式会更优。但是三种方式也会不同程度上引入重名问题。
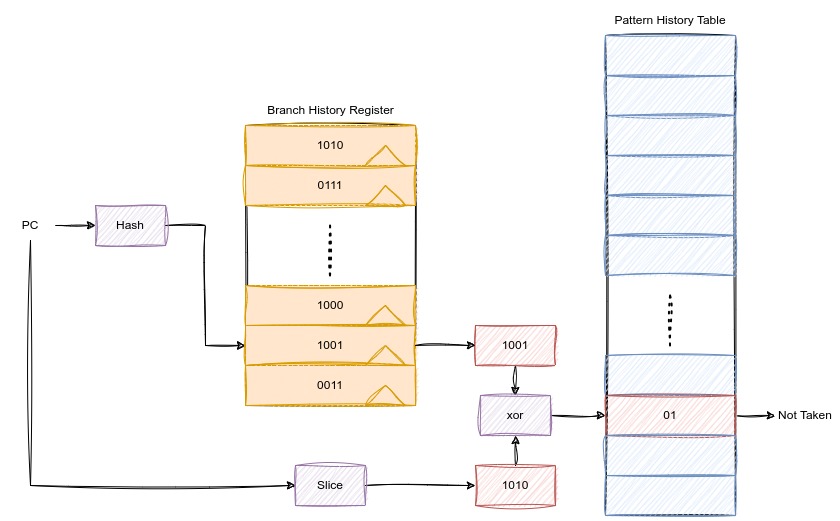
最后一个问题,BHR的位宽值应该取多少呢?这个值取决于分支指令跳转的循环周期。实际上,这个值是无法确定的。所以位宽越大,预测的结果就会更加准确。但是,分支预测训练的时间也会增加。
基于全局历史的分支预测
假设将基于局部历史的分支预测中PC全部哈希成一个值,则全局就只有一个BHR了。这个时候就是基于全局历史的分支预测原型了。
原理
其实和基于部分历史的分支预测的原理一样,这里使用的全部分支指令的历史跳转情况。
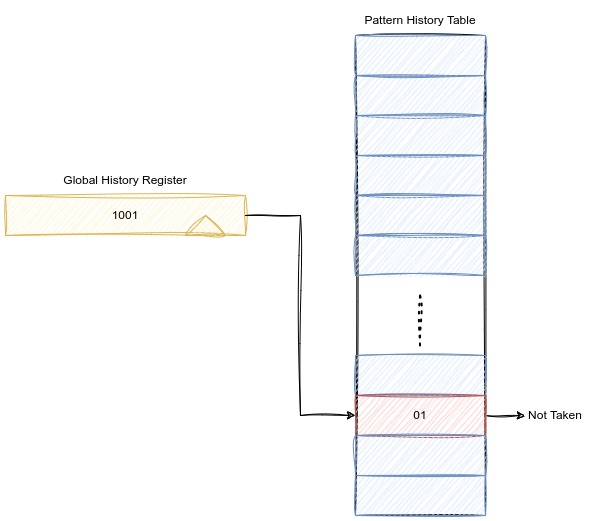
这个时候,我们并没有使用上PC这个值,导致重名的概率会很高。
改进
利用PC,建立多个PHT,使用PC索引PHT。效果如下图: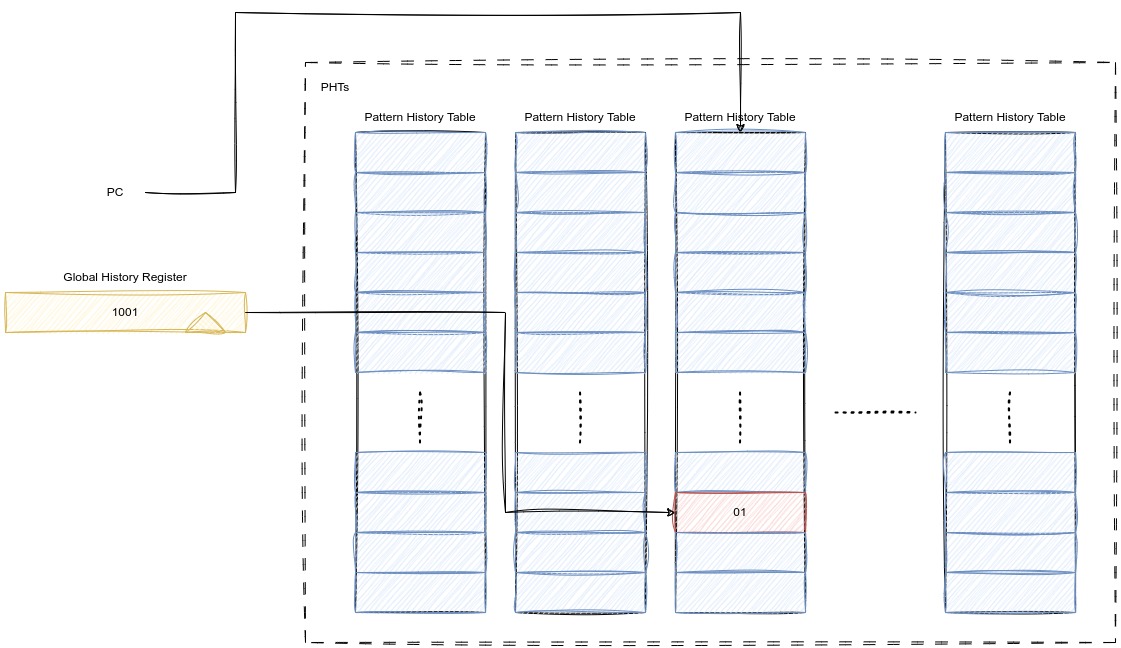
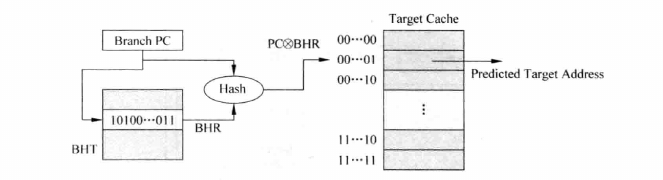
用PC做索引硬件开销大,我们可以用哈希函数优化一下:
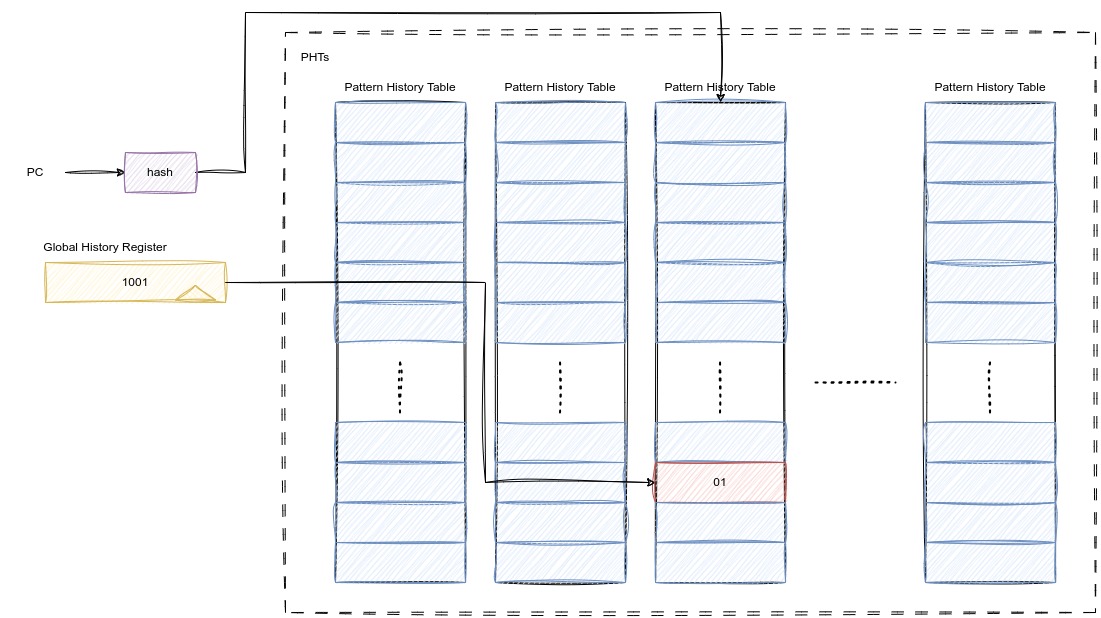
同样,我们也可以仿照基于局部历史的分支预测的改进方式,使用一个PHT,扩大entry的个数,使用一些映射方式将PC转化成索引:
- 位拼接:将PC的哈希值和GHR的值拼接。
- 异或:将PC的哈希值和GHR异或。
在大多数情况下,使用异或的方式会更优。
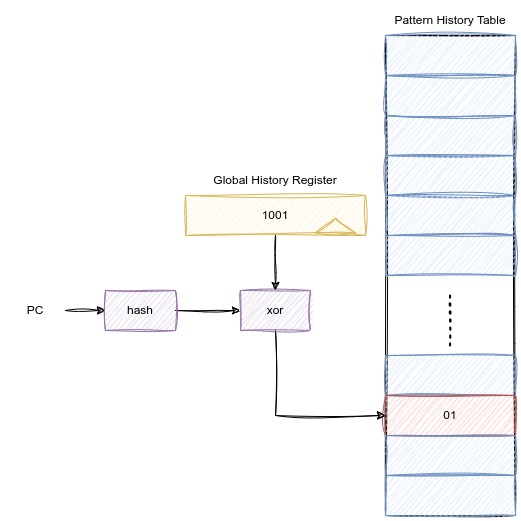
竞争的分支预测
基于局部历史的分支预测以及基于全局历史的分支预测各有优缺点,都有自身的局限性,有些分支指令使用基于局部历史的分支预测会有更好的效果,而有些指令使用基于全局历史的分支预测会有更好的效果。此时,可以设计一种方式,根据分支指令的执行情况来选择合适的分支预测的方式,称为竞争的分支预测。
原理
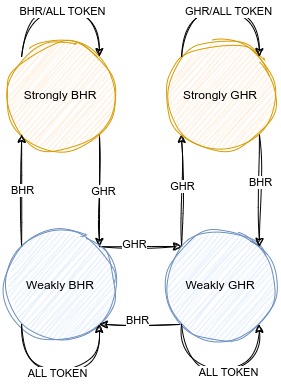
既然分支指令有跳转和不跳转两种情况,可以使用两位饱和计数器来预测;那么,我们可以将分支指令的预测方式分为两种情况,一种基于局部历史的分支预测,一种基于全局历史的分支预测,也可以使用两位饱和计数器来选择使用那种分支预测的方式。针对分支预测方式的PHT,我们称之为CPHT(Choice PHT)。
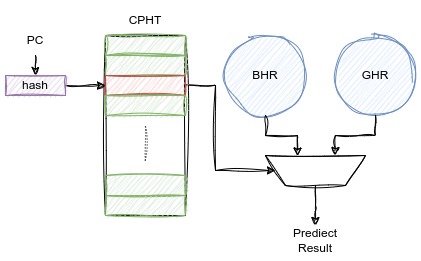
CPHT里的状态机也和PHT的状态机类似,分为强使用BHR,弱使用BHR,弱使用GHR,强使用GHR。状态机图如下:
分支预测的更新
完成分支指令之后,需要对分支预测的历史寄存器以及两位饱和计数器进行更新。
历史寄存器的更新
历史寄存器的更新有三种更新方式:
- 在取指阶段对预测的结果进行更新
- 在分支指令被实际算出来的时候更新
- 在分支指令退休的时候更新
第一种方式更新的结果显而易见是不一定正确的,因为分支指令的结果不确定;第二种方式结果上是正确的,但是有延迟可能会导致该分支指令下面几条指令的预测错误;第三种方式是最保守的,当然也也是最安全的,同样也会出现第二种情况出现的问题。
但是我们想尽快的使用新的分支结果怎么办?此时还是需要在取指的时候对预测结果更新。那么会引入新的问题,预测错误了怎么恢复呢?
书上提供了两种恢复方式:
- 提交阶段恢复法
- checkpoint恢复法
第一种恢复方法是在提交的时候更新分支预测器,即在译码和提交阶段各准备一个GHR寄存器。在译码阶段的GHR寄存器是投机性的,因此不准确。当分支预测错误的时候,使用提交阶段的GHR来更新译码阶段的GHR。
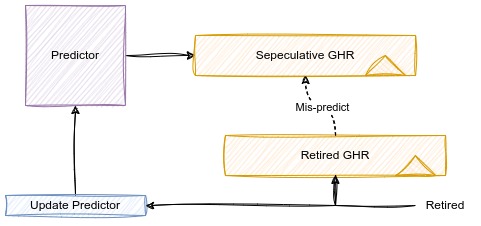
第二种方式是在分支指令计算出来之后对分支预测进行恢复。当在译码阶段预测之后,将预测结果写入到译码阶段的GHR中,同时,也将预测的反结果写到一个FIFO存储器中,当分支预测失败的时候,直接从FIFO中拿出恢复译码阶段的GHR。
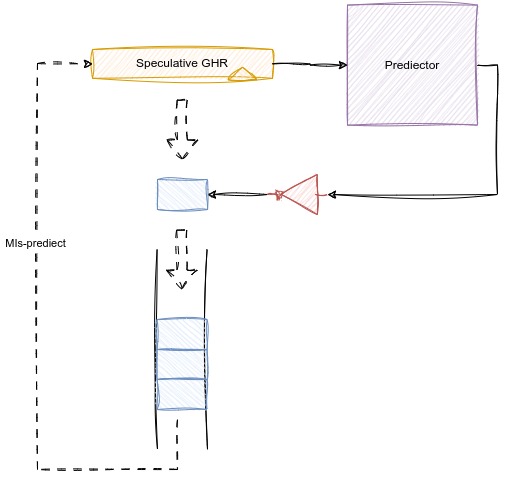
书上总结来讲,在基于全局历史的分支预测方法中,在取指阶段根据分支预测的结果来更新GHR是最合适的,他利用了分支指令之间存在的相关性。而在基于局部历史的分支预测方法中,可以在分支指令退休的时候更新BHR,这样可以简化设计,也不会对处理器性能造成太大的影响。
饱和计数器的更新
一般在分支指令退休的时候对PHT中的饱和计数器进行更新。
分支指令的目标预测
分支指令分为两种,直接跳转指令以及间接跳转指令。
直接跳转指令的分支预测
对于直接跳转的分支指令,他们的目标地址是PC相关的,偏移量以立即数的形式存储在指令中,所以目标地址也是固定的。等同于,PC值映射到一个目标地址值。
原理
联想到缓存,是内存地址映射到一个数据。这里,我们把PC当作地址,目标地址当作数据。那么,我们可以用缓存的思想来解决这个问题。这里的缓存,我们就称之为 BTB(Branch Target Buffer)。
缓存需要的要素,有效位,表示该行缓存有效;tag,用以确定该缓存行对应的地址值,此处称为BIA(Branch Instruction Address);数据块,保存目标跳转地址,此处称之为BTA(Branch Target Address)。
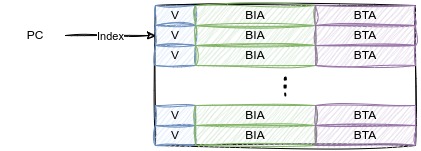
类似于数据缓存,我们将PC分成index和tag两个部分,如下图所示:

缓存都会遇到一个问题就是重名问题,解决方式就是设计成多路。分支预测需要尽快的完成,所以这里的路数要尽可能小。一般采用2路缓存。
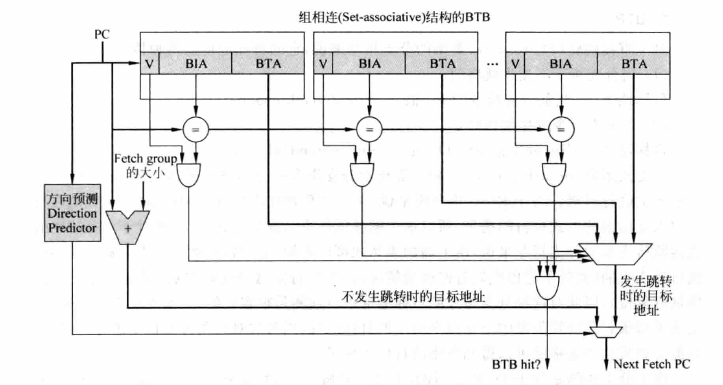
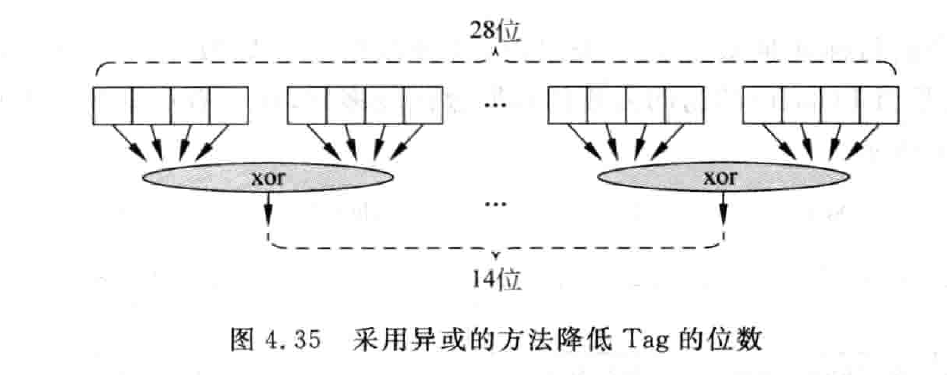
tag对应的是BIA部分,需要对其进行压缩处理。常用的方式:切片,哈希,异或。
BTB缺失的处理
- 停止执行:直到这条分支指令的目标地址被计算出来为止。
- 继续执行:按照顺序执行方式执行指令。
间接跳转指令的预测
对于间接跳转指令,他们的目标地址来自于通用寄存器,是经常变化的,所以无法通过BTB对它的目标地址进行准确的预测。所幸的是,打啊部分间接跳转类型的分支指令都是用来进行子程序调用的CALL/RETURN指令,这两个指令是有规律可循的。
原理
当调用一次call指令的时候,后续程序可能会调用与call指令对应的return指令,有LIFO的效果。故我们可以用栈来维护call指令执行的下一条指令的地址,当遇到return指令的时候,从栈中弹出下一跳指令的地址。
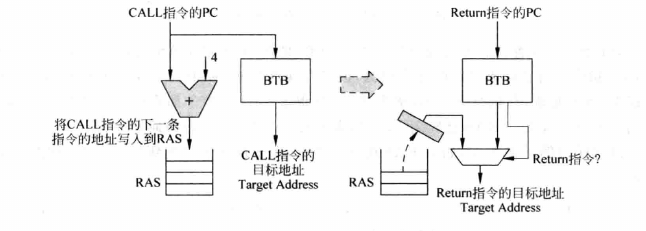
需要考虑的问题,栈的大小是多少。如果大小太小,则能保存的地址不多。当嵌套层数较大的时候,保存的地址就会被覆盖,导致后续的分支预测失败。一般采用的大小为4。
改进
在程序中,其实还存在这样一种情况:函数自己调用自己!此时,return的地址都是一样,我们就没有必要每次都用一个栈空间在存储这个地址。我们可以在栈上维护计数器,来表示每个栈空间上的地址需要调用的次数。这样栈上能保存的个数就不一定是4了。
其他分支指令的预测
其他分支就没固定的目标地址,但是我们也可以借鉴基于局部历史的分支预测方式。之前是预测是否发生跳转,此时,我们预测跳转的目标地址,只需要将PHT里保存的两位饱和计数器换成目标地址即可。
分支预测失败时的恢复
有两种方法:
- 基于ROB(Re-Order Buffer)进行复制预测失败的状态恢复:遇到预测错误的分支指令时,停止后续的取指操作。然后等待已经发射的指令进入到ROB中,将所有分支指令之后的指令抹除掉。这种方式虽然惩罚过大,但是实现简单,硬件开销小,是一种比较折中的方案。
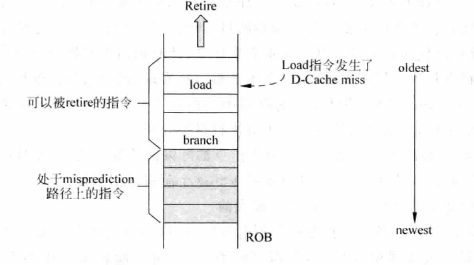
- 使用checkpoint方法进行恢复:遇到分支指令之后,将处理器的状态保存起来,主要是保存寄存器重命名中使用的映射表,预测的分支指令下一条指令的PC值等。这种方法能够快速恢复处理器的状态,效率高,但是硬件消耗就会增大。但是还会有一个问题,需要抹除掉流水线中已经发射的指令。此时就需要使用tag list的方法。
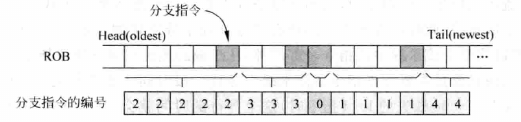
tag list
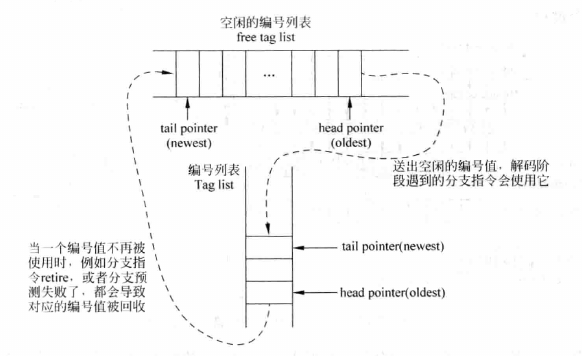
为每一条分支指令提供一个编号tag,所有在此指令之后都使用这个tag。当遇到分支预测错误的时候,使用该抹除ROB中的指令。
那么如何来维护可以使用的tag呢?我们维护两个队列FIFO,一个空闲tag队列,一个tag队列。需要编号的时候,从空闲tag队列中取出一个tag,将其放入tag队列中;当一个tag不再被使用的时候,例如退休和分支预测错误,将其从tag队列中取出,并放入到空闲tag队列中。

Pei Meng
Someone who interested in Computer Architecture.